Breaking the Token Barrier: How Dynamic Chunking (H-Net) Is Redefining AI Text Processing
Martín Marlatto
CSO at WillDom | Partner
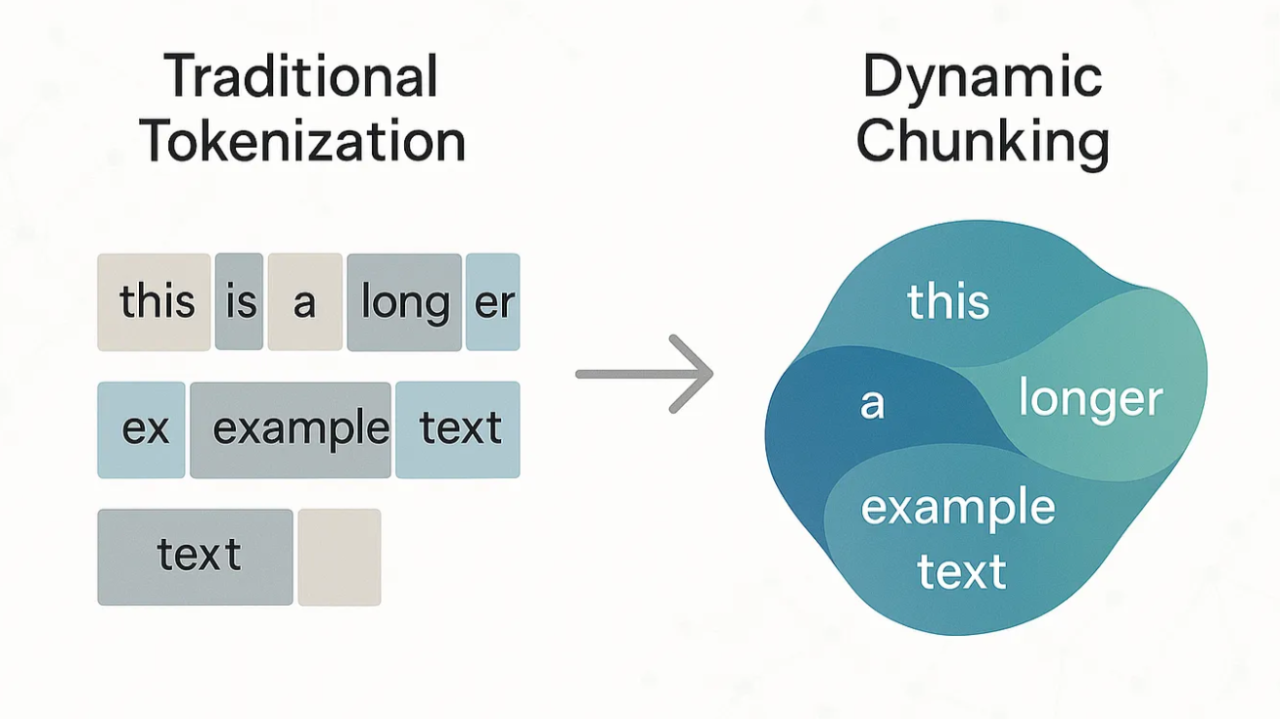
For decades, tokenization has been at the heart of how AI models understand and process text. From Byte-Pair Encoding (BPE) to advanced subword algorithms, tokenization has enabled impressive progress—but it also brings deep-rooted limitations, from language bias to inefficiency and brittleness in the face of typos or non-standard text. As Andrej Karpathy famously put it, "tokenization is where all the pain comes from" in language models.
A new research paper, "Dynamic Chunking for End-to-End Hierarchical Sequence Modeling" by Sukjun Hwang, Brandon Wang, and Albert Gu, proposes a radical shift: what if we could eliminate tokenization altogether? Their answer is the H-Net architecture, a model that learns to segment text dynamically, directly from raw bytes, and does so in a fully end-to-end way.
Why Tokenization Falls Short
Tokenization, especially BPE, breaks text into statistically common fragments. While efficient for English, this approach can split up meaningful units in other languages or even within English words, leading to "junk" tokens that confuse models and waste vocabulary space. As highlighted by recent studies, tokenization introduces biases, especially for languages like Chinese, and makes models fragile to character-level changes or typos.
Enter Dynamic Chunking and H-Net
H-Net replaces the fixed tokenization step with a dynamic, learnable chunking mechanism. Instead of relying on handcrafted rules, H-Net's "routing module" learns to segment text based on semantic and contextual cues, while its "smoothing module" ensures robust, interpretable boundaries. This architecture is inspired by how humans naturally group letters into words and phrases, building abstractions at multiple levels.
What sets H-Net apart is its hierarchical design: it not only learns to chunk at the byte level but can stack layers to build higher-order abstractions—much like how we move from letters, to words, to sentences. This enables the model to scale efficiently, handle languages and modalities with weak tokenization cues (like Chinese or DNA), and match or even surpass the performance of traditional tokenized Transformers of much larger size.
Results and Implications
- Performance: H-Net matches or exceeds strong BPE-tokenized Transformers, especially as more data is seen. In benchmarks, a two-stage H-Net overtakes its tokenized counterpart after just 30B training bytes.
- Robustness: H-Net is dramatically more robust to textual perturbations—like typos or random casing—compared to token-based models.
- Fairness and Multilinguality: By operating at the byte level, H-Net reduces language bias and performs better on languages like Chinese, as well as on code and DNA sequences.
- Interpretability: Visualizations show that H-Net learns meaningful, human-like boundaries without supervision.
As the authors note, "H-Net represents the first truly end-to-end, tokenizer-free language model: with a single stage of dynamic chunking, a byte-level H-Net matches the perplexity and downstream performance of a strong BPE-tokenized Transformer at sizes exceeding 1B parameters." This is a major step towards more universal, fair, and robust AI systems.
Looking Forward
While H-Net is not without challenges—training is more complex and currently slower than traditional models—its approach signals a new era in AI text processing. As Richard Sutton's "bitter lesson" reminds us, methods that best leverage compute and data will ultimately win out. Dynamic chunking could be the next leap forward, finally breaking the token barrier that has defined NLP for decades.
Sources:
- "Dynamic Chunking for End-to-End Hierarchical Sequence Modeling," Sukjun Hwang, Brandon Wang, Albert Gu, arXiv:2507.07955
- "Dynamic Chunking (H-Net): A New Approach to Tokenizer-Free AI Text Processing," Joe El Khoury, Medium
Enhanced by ChatGPT